非接触式唇读和声学分析的综合数据集为语音识别技术带来了潜力
研究人员表示,对产生语音的物理过程进行复杂的新分析可以帮助有语言障碍的人增强能力,并为语音识别技术创造新的应用。
格拉斯哥大学的工程师和物理学家领导了这项研究,该研究使用各种传感设备仔细检查了志愿者说话时的内部和外部肌肉运动。
格拉斯哥团队正在向其他研究人员免费提供 400 分钟分析数据,以帮助开发基于语音的新技术认可。
这些未来的技术可以通过使用传感器读取他们的嘴唇和面部动作并为他们提供合成声音来帮助患有言语障碍或失声的人们。
该数据集可以让智能手机等语音控制设备读取用户的信息。当他们无声说话时,嘴唇,从而实现无声语音识别。它还有助于增强语音识别,提高视频和通话质量在嘈杂的环境中。
它甚至可以通过分析用户的行为来帮助提高银行或机密交易的安全性。在解锁敏感存储信息之前,需要进行独特的面部动作,例如指纹。
研究人员在题为“用于非接触式唇读和声学分析的综合多模态数据集<的论文中讨论了他们如何对语音形成进行多模态分析” a i=2>,”在期刊科学数据。
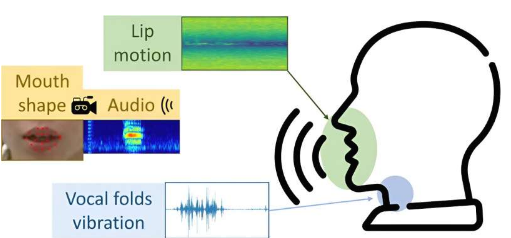
为了收集数据,研究人员要求 20 名志愿者说出一系列元音、单个单词和整个句子,同时收集他们面部动作的复杂扫描和声音录音。
该团队使用两种不同的雷达技术——脉冲电超宽带(IR-UWB)和调频连续波(FMCW)协议来对志愿者的运动进行成像。他们说话时的面部皮肤,以及舌头和喉部的运动。
同时,使用激光散斑检测系统扫描皮肤表面的振动,该系统使用高速相机捕捉振动发射激光散斑的振动。一个独立的 Kinect V2 摄像头能够测量深度,读取他们发出不同声音时嘴巴的变形。
格拉斯哥大学研究人员与邓迪大学和伦敦大学学院的同事合作同步和编译该数据集,他们将其称为 电频率的 RVTALL,其包含的视觉、文本、音频、激光和唇部标志信息。
数据经过信号处理和机器学习技术的验证,构建了人们形成声音的物理机制的独特详细图像.
格拉斯哥大学詹姆斯·瓦特工程学院的 Qammer Abbasi 教授是该论文的通讯作者。阿巴西教授此前曾领导过语音识别研究,该研究使用多模态传感通过面具读取嘴唇运动。
阿巴西教授说:“这种用于语音识别的多模态传感仍然是一个相对较新的研究领域,我们对现有公共数据的审查发现,没有太多可用于帮助支持未来发展的数据。
“我们收集 RVTALL 数据集的目的是对可见和不可见的过程创建一套更完整的分析,这些过程产生语音以实现新的研究突破,我们很高兴我们能够现在可以分享它了。”
格拉斯哥大学通信、传感和成像中心负责人 Muhammad Imran 教授是该论文的合著者。他表示,“非接触式传感在改进语音识别和创建新应用<方面具有巨大潜力。 a i=4> 通信、医疗保健和数字安全。
“我们格拉斯哥大学自己的研究小组热衷于探索如何利用多模态传感器在唇读方面取得突破,并在从家庭到医院的各个地方找到新的用途。”
免责声明:本答案或内容为用户上传,不代表本网观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。 如遇侵权请及时联系本站删除。